




I. Introduction▲
DFSORT est un outil crucial dans les traitements z/OS┬Ā: celui-ci a ├®t├® am├®lior├® depuis des dizaines d'ann├®es pour offrir un nombre tr├©s large de fonctionnalit├®s. Il peut travailler avec des VSAM ou des QSAM, et si les fonctionnalit├®s ne sont pas pr├®sentes dans le produit de base, des PTFs (┬½┬Āadd-ons┬Ā┬╗ ou ┬½┬Āplug-ins┬Ā┬╗ dans le vocabulaire IBM Mainframe) et des Exits (┬½┬Āhooks┬Ā┬╗ sur certaines routines pour appliquer ses propres traitements au lieu de ceux pr├®vus) permettent de s'adapter aux besoins exacts.
Les tris internes li├®s aux compilateurs sont certes efficaces, mais n├®cessitent de recompiler ou relinker les programmes lorsque de nouvelles versions sont disponibles. De plus, si l'on souhaite changer certaines informations ou trier diff├®remment, il faut recompiler. Pour toutes ces raisons, l'externalisation du tri par rapport au traitement applicatif a ├®t├® retenue. Dans le contexte batch, c'est une solution simple ├Ā mettre en place, et tr├©s flexible.
Ce tutoriel a ├®t├® r├®dig├® environ 1 an et demi apr├©s mes premiers pas sur z/OS, il s'agit donc d'un tutoriel pour d├®butants┬Ā: les m├®thodes employ├®es sont tr├©s simples et diversifi├®es pour avoir le plus d'exemples concrets disponibles. L'exemple pr├®sent├® peut ├¬tre r├®alis├® de plusieurs autres mani├©res, mais pour apprendre il vaut mieux r├®p├®ter/├®crire plusieurs fois la m├¬me chose.
II. Description▲
Dans ce tutoriel, on expliquera quelques commandes et fonctionnalit├®s du DFSORT telles que┬Ā: le filtre, le tri, la r├®├®criture de valeurs, la comparaison avec des dates, la suppression de doublons et la jointure de 2 datasets (les ┬½┬Āfichiers┬Ā┬╗ au sens Mainframe).
On abordera ├®galement quelques programmes communs┬Ā: IEBGENER et ICEGENER pour la copie de donn├®es vers des datasets et le changement de format d'enregistrement (passage de FB, Fixe Blocked, ├Ā VB, Variable Blocked, car les datasets sont de taille et formats limit├®s).
L'analyse des logs et des STC (Started Task, ├®quivalents des services ou daemons sur Windows et UNIX) se fera avec le programme SDSF, dont une version avec plus de fonctionnalit├®s existe┬Ā: ISFAFD.
III. DFSORT▲
L'outil DFSORT est disponible sous diff├®rents formats┬Ā: fonction pour du d├®veloppement, commande de script ou bien programme ├Ā appeler. On se concentrera sur le programme ┬½┬ĀSORT┬Ā┬╗ ├Ā appeler en JCL.
La documentation officielle est tr├©s charg├®e, mais compl├©te. Ce tutoriel a ├®t├® r├®dig├® pour faciliter l'utilisation de base, mais il ne faut pas h├®siter ├Ā aller chercher dans la documentation ou l'Infocentre IBM (publib.boulder.ibm.com, pic.dhe.ibm.comŌĆ”)┬Āpour plus de d├®tails┬Ā!
III-A. Processing/Pipeline de traitement▲
Avant toute utilisation de SORT, il est important de conna├«tre l'ordre dans lequel celui-ci va effectuer les instructions que nous allons lui passer. En effet, ├Ā chaque ├®tape (step) utilisant SORT, on va effectuer un traitement (tri ou copie) entour├® par plusieurs pr├®-traitements (sauts de N enregistrements, filtre, et r├®organisation) et plusieurs post-traitements (r├®organisation, et de multiples ordres).
Le sch├®ma fourni par IBM est tr├©s complet et permet de voir la progression dans le pipeline┬Ā:
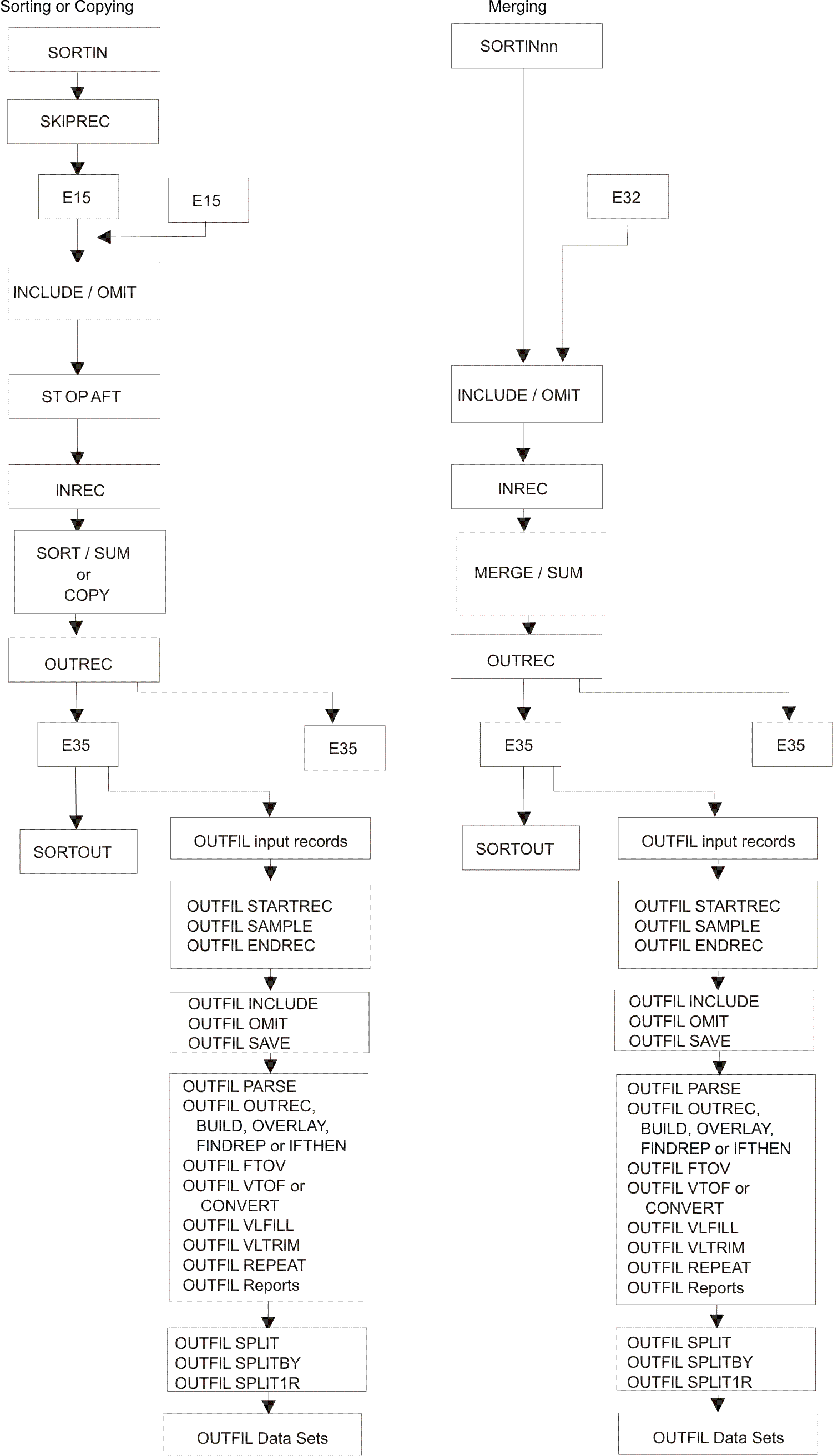
On se concentrera sur les ├®tapes simples pour faciliter l'approche┬Ā:
- SORTIN┬Ā: c'est le nom de la carte DD d'entr├®e, on va donc ins├®rer les donn├®es dans le pipeline avec elle.
- SKIPREC┬Ā: instruction en SYSIN, c'est une instruction indiquant combien d'enregistrements on va d├®passer avant de commencer le traitement (utile si on a des commentaires avant les donn├®es).
- INCLUDE/OMIT┬Ā: on indique ici un crit├©re pour filtrer les donn├®es, soit on inclut en fonction d'un crit├©re, soit on omet en fonction d'un crit├©re.
- STOPAFT┬Ā: on indique le nombre maximum d'enregistrements que l'on veut traiter, ┬½┬ĀSTOP AFTer┬Ā┬╗ tout simplement.
- INREC┬Ā: si l'on souhaite r├®organiser les colonnes ┬½┬Āavant┬Ā┬╗ le traitement, cela permet de placer certaines valeurs sur certaines colonnes.
- SORT/SUM ou COPY┬Ā: c'est le traitement principal┬Ā! Soit on trie (ordre ascendant/descendant en fonction de certaines colonnes), soit on copie. Dans tous les cas, seuls les enregistrements qui arrivent ├Ā cette ├®tape seront trait├®s et appara├«tront sur la sortie pr├®vue.
- OUTREC┬Ā: similaire ├Ā INREC mais ┬½┬Āapr├©s┬Ā┬╗ traitement, on peut r├®organiser les colonnes, faire des calculs, changer certaines valeurs par d'autresŌĆ”
- [SORTOUT]┬Ā: si on n'ajoute pas d'instruction OUTFIL, alors les enregistrements qui sont arriv├®s jusque-l├Ā sont recopi├®s en SORTOUT et le step est termin├®.
- [OUTFIL]┬Ā: si une ou plusieurs instructions OUTFIL sont ins├®r├®es, elles d├®marrent ├Ā partir de l├Ā. On ne pr├®sentera pas les clauses OUTFIL, car on ne les abordera quasiment pas. Ce qu'il faut retenir┬Ā: un autre pipeline de traitements est g├®r├® par OUTFIL, on peut donc effectuer des traitements suppl├®mentaires avec.
III-B. Sauter des enregistrements (SKIPREC)▲
On peut sauter N enregistrements gr├óce ├Ā la clause SKIPREC. Cela est tr├©s utile si le dataset est d├®marr├® par des commentaires.
Exemple┬Ā:
2.
SORT FIELDS=(1,20,CH,A)
OPTION SIZE=50000,SKIPREC=5,EQUALS,DYNALLOC
Ici, on va sauter les 5 premiers enregistrements avant de continuer.
III-C. Maximum d'enregistrements (STOPAFT)▲
On sp├®cifie ici le maximum d'enregistrements que l'on veut traiter.
Exemple┬Ā:
OPTION STOPAFT=100
Ici, on va s'arr├¬ter apr├©s 100 enregistrements lus.
Si on le combine avec le SKIPREC, il faut repenser au pipeline┬Ā: on va d'abord ignorer les N premiers enregistrements, on va ensuite filtrer avec INCLUDE/OMIT, puis compter les enregistrements restants jusqu'├Ā atteindre le maximum.
Exemple:
Avec en entr├®e des enregistrements de 1 ├Ā 10, et cette ligne┬Ā:
OPTION COPY,SKIPREC=4,STOPAFT=3
On aura en sortie les enregistrements 5 ├Ā 7 qui seront trait├®s┬Ā: les 4 premiers sont ignor├®s, puis on prend le 5, le 6 et le 7 (3 enregistrements sont pass├®s), puis on s'arr├¬te.
Cette option est utile lorsque l'on veut tester sur de tr├©s gros volumes┬Ā: on prend un ├®chantillon.
III-D. Filtrer les enregistrements (INCLUDE/OMIT)▲
Avant de trier, on peut vouloir ne s├®lectionner que certaines lignes, ou effectuer un traitement sur certaines valeurs pr├®cises. Dans ce cas, on peut pr├®alablement filtrer les lignes qui seront trait├®es avec les instructions INCLUDE et OMIT.
Si le but du step est ┬½┬Āuniquement┬Ā┬╗ de filtrer certaines valeurs, au lieu d'indiquer un traitement de tri, on va indiquer que l'on souhaite seulement copier les enregistrements r├®pondant aux crit├©res de s├®lection.
Exemple┬Ā:
2.
INCLUDE COND=(1,80,SS,EQ,C'ABC')
SORT FIELDS=COPY
Ici, on va copier les enregistrements (sans trier) o├╣ l'on arrive ├Ā trouver la cha├«ne ┬½┬ĀABC┬Ā┬╗ depuis la colonne 1 sur 80 octets.
Le mot INCLUDE peut ├¬tre remplac├® par OMIT pour inverser l'inclusion┬Ā:
OMIT COND=(1,80,SS,EQ,C'ABC')
Ici, on va ├®viter tous les enregistrements contenant la cha├«ne ┬½┬ĀABC┬Ā┬╗ depuis la colonne 1 sur 80 caract├©res.
Il est possible d'effectuer plusieurs conditions avec des ┬½┬ĀAND┬Ā┬╗ et ┬½┬ĀOR┬Ā┬╗┬Ā:
OMIT COND=((1,3,CH,EQ,C'LOL'),AND,(4,3,CH,EQ,C'MDR'))
Ici, on va retirer les enregistrements contenant simultan├®ment ┬½┬ĀLOL┬Ā┬╗ depuis la colonne 1 sur 3 caract├©res et ┬½┬ĀMDR┬Ā┬╗ depuis la colonne 4 sur 3 caract├©res.
Il est possible d'interpr├®ter les champs de diff├®rentes mani├©res┬Ā:
CH (CHaracter) signifie que l'on interpr├©te le champ comme une cha├«ne de caract├©res, il faut donc la comparer avec une autre cha├«ne d├®clar├®e avec C'ŌĆ”'. La comparaison se fait strictement dans les bornes indiqu├®es.
SS (SubString) signifie que l'on cherche une cha├«ne de caract├©res dans les bornes indiqu├®es. Il s'agit bien d'une recherche de sous-cha├«ne, on peut donc indiquer l'ensemble de l'enregistrement pour rechercher une cha├«ne dedans.
ZD (Zone Decimal) signifie que l'on a des nombres inscrits sous formes de caract├©res (┬½┬Ā42┬Ā┬╗ par exemple). On peut les comparer avec d'autres valeurs┬Ā: ┬½┬Ā(31,6,ZD,GT,2500)┬Ā┬╗ on va comparer les 6 caract├©res avec la valeur 2500.
Y2T, Y4TŌĆ” sont des formats de dates. On peut ainsi comparer ces valeurs avec diff├®rentes dates autour du jour courant┬Ā: ┬½┬Ā(23,5,Y2T,EQ,Y'DATE3')┬Ā┬╗ ici la date lue est sur 5 caract├©res, est au format Y2T (14001┬Ā: 1er jour de l'an 2014) et est compar├®e ├Ā la date du jour au m├¬me format (Y'DATE3' donne la date du jour dans le format ┬½┬ĀDATE3┬Ā┬╗). Il est possible de comparer avec le lendemain (Y'DATE3'+1) ou la veille┬Ā(Y'DATE3'-1) sur 30 jours. Beaucoup d'autres formats de dates existent.
On peut interpr├®ter les champs de nombreuses fa├¦ons, mais on a pr├®sent├® les 4 m├®thodes simples pour des travaux de d├®butant. L'ensemble des formats se trouve ici┬Ā: DFSORT Data Formats
En plus de l'├®galit├® (EQ), on peut tester l'in├®galit├® (NE). Dans le cas des nombres ou des dates on peut tester les habituels ┬½┬Āplus grand que┬Ā┬╗ (GT), ┬½┬Āplus grand ou ├®gal┬Ā┬╗ (GE), ┬½┬Āplus petit que┬Ā┬╗ (LT), ┬½┬Āplus petit ou ├®gal┬Ā┬╗ (LE).
III-E. Trier les enregistrements (SORT)▲
On a vu comment copier sans modifier les enregistrements, en utilisant le mot ┬½┬ĀCOPY┬Ā┬╗, mais on peut vouloir trier en fonction de plusieurs crit├©res. Gr├óce aux formats vus, SORT va comparer et trier en fonction de ces crit├©res.
Il s'agit du ┬½┬Ātraitement┬Āprincipal┬Ā┬╗ au centre du pipeline. Il y a donc des modifications possibles ├Ā faire avant et apr├©s le tri.
Exemple┬Ā:
SORT FIELDS=(1,80,CH,A)
On trie de fa├¦on ascendante (A final), en fonction des caract├©res (CH) dans le champ d├®marrant en colonne 1 sur 80 caract├©res. Pour trier de fa├¦on descendante, il suffit de remplacer le ŌĆśA' par un ŌĆśD'.
Il est possible de trier sur plusieurs crit├©res (en cas de cl├®s primaires en plusieurs exemplaires)┬Ā:
SORT FIELDS=(5,5,ZD,A,12,6,PD,D,21,3,PD,A,35,7,ZD,A)
La cl├® primaire sera la premi├©re d├®clar├®e (5,5,ZD,A┬Ā: tri de fa├¦on ascendante sur un ID num├®rique sur 5 posits depuis la colonne 5), et on avance vers les cl├®s d'importances moindres.
III-F. Supprimer les doublons (SUM)▲
La suppression des doublons intervient dans le cadre d'un tri. Les doublons sont d├®duits en fonction des cl├®s┬Ā! Si tous les champs sont ├Ā prendre en compte, il faut donc expliciter chaque champ ou l'ensemble de l'enregistrement.
SUM fonctionne en temps normal comme additionneur pour les champs en multiples exemplaires, mais en explicitant le fait que l'on ne veut PAS additionner, celui-ci va retirer les doublons et ┬½┬Āne pas┬Ā┬╗ effectuer d'addition entre les entr├®es en double. SUM est donc une instruction ├Ā double usage.
Exemple┬Ā:
2.
SORT FIELDS=(1,80,CH,A)
SUM FIELDS=NONE
Ici, on va trier de fa├¦on ascendante sur les 80 premi├©res colonnes, et supprimer tous les enregistrements en double.
SUM Control Statement
III-G. Modifier les valeurs ou les colonnes (INREC, OUTREC, OUTFIL)▲
La modification de valeurs ou de colonnes intervient dans les phases avant et apr├©s traitement. En effet, si l'on souhaite reformater les donn├®es ou n'utiliser que certaines d'entre elles, on peut en extraire une partie et ignorer les autres.
Attention┬Ā: si on modifie les champs ┬½┬Āavant┬Ā┬╗ traitement, il faudra penser ├Ā trier en fonction des nouvelles colonnes┬Ā!
Il existe plusieurs syntaxes possibles pour d├®crire les champs et les placements. Jusqu'├Ā maintenant, on a seulement d├®crit les champs dans le format┬Ā:
colonne du 1er caract├©re,longueur ├Ā prendre en compte
Mais il est possible de d├®crire d'une autre fa├¦on le format que l'on souhaite obtenir┬Ā:
colonne de sortie o├╣ d├®marrer:colonne du 1er caract├©re en entr├®e ├Ā copier,longueur
Exemple┬Ā:
2.
3.
4.
5.
6.
INREC FIELDS=(1:8,7,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 9:26,7,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 17:35,8,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 26:44,4,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 31:51,6,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 38:62,6)
┬½┬Ā1:8,7┬Ā┬╗ On va copier sur la 1re colonne de sortie 7 caract├©res d├®marrant ├Ā la colonne 8, etc.
Ce qui donnerait en entr├®e┬Ā:
| 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| x | x | x | x | x | x | x | x | A | B | C | D | E | F | G | x | x | x |
Et en sortie┬Ā:
| 01 | 02 | 03 | 04 | 05 | 06 | 07 |
| A | B | C | D | E | F | G |
On peut ├®galement ajouter des espaces au lieu de laisser des ŌĆś0' binaires. En effet, si on souhaite transf├®rer des datasets vers des syst├©mes ouverts (UNIX, Linux, Windows), il vaut mieux ne pas laisser de caract├©res signifiant la fin d'une cha├«ne, surtout quand il s'agit de commandes ou de balises qui seront interpr├®t├®es. La syntaxe est simplement le nombre d'espaces voulus suivi d'un ŌĆśX'.
Exemple┬Ā:
OUTREC BUILD=(1,43,167X)
On va copier les 43 premiers caract├©res, et ajouter 167 espaces.
Dans ces 2 exemples, on a par ailleurs r├®organis├® le fichier ┬½┬Āavant┬Ā┬╗ traitement (INREC) et ┬½┬Āapr├©s┬Ā┬╗ traitement (OUTREC).
Dans les traitements additionnels, on trouve l'op├®rande OUTFIL. L'un des usages possibles est de reformater la sortie pr├®vue. OUTFIL OUTREC ou OUTFIL BUILD permettent cela┬Ā:
OUTFIL OUTREC=(12,5,21,8,29,12,41,9,60,120,86X)
Ici, on retrouve un ordre tr├©s similaire aux exemples pr├®c├®dents. OUTFIL permet beaucoup plus que cela. En effet, il permet d'envoyer diff├®rents traitements vers plusieurs datasets. Il est ├®galement possible de sortir vers un dataset les enregistrements retir├®s via les diff├®rents filtres.
On peut aussi appliquer des conditions et transformer en fonction de certaines valeurs┬Ā:
2.
3.
4.
5.
6.
7.
8.
INREC IFTHEN=(WHEN=(45,2,CH,EQ,C'OK'),
┬Ā┬Ā BUILD=(1,44,45:C'<FONT COLOR="GREEN">OK</FONT>',200X)),
┬Ā┬Ā IFTHEN=(WHEN=NONE,
┬Ā┬Ā┬Ā┬Ā BUILD=(1,44,45:C'<FONT COLOR="RED">KO</FONT>',202X))
OUTREC BUILD=(C'<TR><TD>',
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 1,7,C'</TD><TD>',
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 9,44,C'</TD><TD>',
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 45,100)
Si on trouve un ┬½┬ĀOK┬Ā┬╗ en colonne 45, alors on va le remplacer par un ┬½┬ĀOK┬Ā┬╗ encadr├® de balises HTML en vert, sinon, dans tous les autres cas on affiche un ┬½┬ĀKO┬Ā┬╗ en rouge avec du HTML.
III-H. Les Jointures▲
L'un des points fort de DFSORT est qu'il poss├©de de multiples PTFs aux fonctionnalit├®s vari├®es, l'une d'elle est la gestion des jointures entre deux fichiers (PTFs UK51706 et UK51707 (SORTUGPG)). La jointure de DFSORT est similaire ├Ā ce que l'on retrouve dans les bases de donn├®es┬Ā: il s'agit de s├®lectionner des enregistrements qui ont des valeurs en commun. Un exemple simple┬Ā: un fichier contient le nom des clients et un ID, l'autre fichier contient les diff├®rents livrets et l'ID associ├® ├Ā chacun, la jointure va permettre de cr├®er en sortie un fichier avec le nom des clients associ├®s aux livrets.
Les pr├®c├®dentes instructions permettaient d'effectuer de multiples op├®rations internes au fichier, mais il arrive que l'on souhaite lier plusieurs fichiers et en extraire plusieurs valeurs┬Ā: les enregistrements ayant un lien dans deux fichiers, les enregistrements n'apparaissant que dans un seul fichier, la somme totale de valeurs d'une cl├® dans les fichiersŌĆ”
Pour cela, on va utiliser les jointures ┬½┬Āinternes┬Ā┬╗ (inner join), et les jointures ┬½┬Āexternes┬Ā┬╗ plus permissives (outer join, full outer join).
III-H-1. Processing/Pipeline jointures▲
Comme pour le tri classique, DFSORT a un pipeline pr├®cis d'op├®rations ├Ā respecter. Voici le sch├®ma fait par IBM pour d├®crire l'ordre des op├®rations┬Ā:

Les principales ├®tapes qui nous int├®ressent pour ce tutoriel sont┬Ā:
- SORTJNF1/SORTJNF2┬Ā: c'est le nom de la carte DD d'entr├®e, on va donc ins├®rer les donn├®es dans le pipeline avec elle. Le nom des cartes DD peut ├¬tre modifi├® si on souhaite effectuer des op├®rations complexes. F1 correspond ├Ā la carte SORTJNF1, et F2 ├Ā SORTJNF2.
- Un premier pipeline similaire ├Ā celui du SORT est effectu├® sur chacun des datasets. Ce pipeline est distinct pour chaque dataset. Cette ├®tape est optionnelle et est ├Ā indiquer en DD JNF1CNTL/JNF2CNTL si on souhaite la personnaliser (un SORT ou un COPY sera effectu├® en fonction de la SYSIN qui contient l'ordre de JOIN). On retrouvera donc les op├®rations┬Ā:
- SKIPREC┬Ā: le nombre d'enregistrements en d├®but de dataset ├Ā ignorer┬Ā;
- INCLUDE/OMIT┬Ā: crit├©re(s) pour filtrer les donn├®es┬Ā;
- STOPAFT┬Ā: le nombre maximum d'enregistrements que l'on veut traiter┬Ā;
- INREC┬Ā: r├®organisation des colonnes ┬½┬Āavant┬Ā┬╗ le traitement┬Ā;
- SORT/SUM ou COPY┬Ā: par d├®faut, un tri est effectu├® sur chaque fichier, mais si on indique ├Ā DFSORT que le dataset est d├®j├Ā tri├® (en ajoutant ┬½┬ĀSORTED┬Ā┬╗), alors un simple COPY sera effectu├®.
- JOINKEYS & JOIN┬Ā: Les fichiers sont r├®cup├®r├®s par l'Exit E15 dans les 2 pipelines, et sont joints en respectant les ordres donn├®s en SYSIN. On peut utiliser la commande REFORMAT pour apporter d'autres modifications.
- Un second pipeline de fin est positionn├® afin de faire un post-traitement si n├®cessaire. Ces op├®rations sont ├Ā indiquer en SYSIN┬Ā:
- INCLUDE/OMIT┬Ā: crit├©re(s) pour filtrer les donn├®es┬Ā;
- STOPAFT┬Ā: le nombre maximum d'enregistrements que l'on veut traiter┬Ā;
- INREC┬Ā: r├®organisation des colonnes ┬½┬Āavant┬Ā┬╗ le traitement┬Ā;
- SORT/SUM ou COPY┬Ā: un SORT ou un COPY avant sortie est n├®cessaire. En effet, on a li├® en fonction de plusieurs cl├®s, mais on peut vouloir trier sur d'autres crit├©res en sortie (on a li├® sur un ID, mais on va trier sur le nom)┬Ā;
- OUTREC┬Ā: r├®organisation des colonnes ┬½┬Āapr├©s┬Ā┬╗ le traitement┬Ā;
- [SORTOUT]┬Ā: si on n'ajoute pas d'instruction OUTFIL, recopie en SORTOUT des enregistrements, et step termin├®┬Ā;
- [OUTFIL]┬Ā: si une ou plusieurs instructions OUTFIL sont ins├®r├®es, les ordres sont effectu├®s.
III-H-2. JOINKEYS statement▲
Avant de faire une jointure, on va d'abord d├®clarer les champs qui serviront de cl├® pour la jointure sur chacun des datasets. Plusieurs options sont disponibles pour l'appel des datasets, on utilisera les noms et options de nommage par d├®faut (FILE=F1/F2 avec SORTJNF1/SORTJNF2).
Le choix du ou des champs de jointure est important (param├©tre┬Ā┬½┬ĀFIELDS┬Ā┬╗). Il fonctionne exactement comme le SORT, c'est-├Ā-dire qu'on lui indique un ou des champs sous forme ascendante ou descendante.
On a donc deux JOINKEYS ├Ā indiquer pour joindre les datasets.
Exemple┬Ā:
2.
JOINKEYS FILE=F1,FIELDS=(26,8,A)
JOINKEYS FILE=F2,FIELDS=(17,8,A)
Ici, la cl├® de jointure se trouve sur 8 caract├©res, elle d├®marre en position 26 dans le dataset donn├® en SORTJNF1, et elle commence en position 17 dans le dataset associ├® ├Ā SORTJNF2.
Si on indique que le dataset est d├®j├Ā tri├® sur cette cl├® (param├©tre ┬½┬ĀSORTED┬Ā┬╗), alors DFSORT ne fera pas de v├®rification, mais il s'arr├¬tera d├©s que le dataset comportera une erreur de tri.
En plus du param├©tre ┬½┬ĀSORTED┬Ā┬╗, on peut forcer en ajoutant ┬½┬ĀNOSEQCK┬Ā┬╗┬Ā: aucune erreur ne sera remont├®e. ┬½┬ĀNOSEQCK┬Ā┬╗ est ignor├® si ┬½┬ĀSORTED┬Ā┬╗ n'est pas indiqu├®.
Exemples┬Ā:
2.
JOINKEYS FILE=F1,FIELDS=(26,8,A),SORTED
JOINKEYS FILE=F1,FIELDS=(26,8,A),SORTED,NOSEQCK
Les ordres INCLUDE/OMIT plac├®s apr├©s le JOINKEYS seront ex├®cut├®s sur le dataset li├®, mais il est plut├┤t recommand├® de le placer en DD JNF1CNTL/JNF2CNTL en cas d'expression complexe┬Ā:
2.
JOINKEYS FILE=F1,FIELDS=(26,8,A),INCLUDE=ALL
JOINKEYS FILE=F2,FIELDS=(17,8,A),INCLUDE=ALL
III-H-3. REFORMAT statement▲
Les deux datasets vont ├¬tre joints, mais il est important de d├®clarer comment ceux-ci vont ├¬tre ├®crits en sortie. C'est le r├┤le de REFORMAT. De plus, il permet d'├®crire dans certains cas si l'enregistrement actuellement g├®n├®r├® a ├®t├® trouv├® dans F1, F2 ou les deux.
Le caract├©re ŌĆś┬Ā?' devient┬Ā:
- ŌĆśB' si l'enregistrement est pr├®sent dans les deux datasets (inner join)┬Ā;
- ŌĆś1' s'il est pr├®sent dans F1 uniquement (left join)
- ŌĆś2' s'il est pr├®sent dans F2 uniquement (right join).
Exemple┬Ā:
REFORMAT FIELDS=(F2:1,43,?,F1:45,156)
Ici, on va copier les 43 premiers caract├©res provenant de F2 (F2:1,43), on ins├©re le caract├©re permettant de d├®clarer o├╣ se trouvait l'enregistrement (ŌĆś?'), puis on ins├©re 156 caract├©res provenant de la 45e colonne de F1 (F1:45,156).
Le format d'enregistrement en sortie va d├®pendre de la d├®claration du JOIN. Si on choisit de faire une jointure externe sur un des deux datasets (left/right outer join), alors celui-ci sera utilis├® comme r├®f├®rence (LRECL sera le m├¬me, et RECFM sera variable ou fixe). Si on choisit d'inclure tous les enregistrements (full outer join), alors le format de sortie sera variable.
On peut d'ailleurs remplir les espaces en trop avec certains caract├©res si le REFORMAT est plus petit┬Ā:
REFORMAT FIELDS=(F2:1,43,?,F2:45,156),FILL=C'X'
Ici, on remplit de caract├©res ŌĆśX' l'espace restant.
III-H-4. JOIN statement▲
Le mot cl├® JOIN sert uniquement ├Ā sp├®cifier le type de jointure externe voulue. En effet, si l'on souhaite une jointure interne (inner join), il suffit de ne pas l'indiquer.
III-H-4-a. Jointures Internes▲
Comme dit pr├®c├®demment, la jointure interne s'effectue tr├©s facilement┬Ā: on indique les JOINKEYS, et DFSORT sortira exclusivement les enregistrements pr├®sents dans les 2 datasets avec la cl├® donn├®e.
Concr├©tement┬Ā:
| SORTJNF1 | SORTJNF2 | SYSIN | SORTOUT |
| ABC,142 | 101,800F | JOINKEYS FILE=F1,FIELDS=(5,3,A) JOINKEYS FILE=F2,FIELDS=(1,3,A) REFORMAT FIELDS=(F1:1,3,F2:4,5),FILL=C' ' |
ABC,200F |
| DEF,337 | 142,200F | GHU,400F | |
| GHU,856 | 856,400F | ┬Ā |
III-H-4-b. Jointures Externes▲
Il existe plusieurs types de jointures externes. Celles-ci permettent d'inclure les enregistrements n'ayant d'existence que dans un des deux datasets (la cl├® est pr├®sente dans un dataset, mais pas dans l'autre).
La jointure permettant d'inclure ┬½┬Ātous┬Ā┬╗ les enregistrements est appel├®e dans les bases de donn├®es ┬½┬Āfull outer join┬Ā┬╗, en DFSORT on la codera ainsi┬Ā:
┬½┬ĀJOIN UNPAIRED,F1,F2┬Ā┬╗ ou plus simplement ┬½┬ĀJOIN UNPAIRED┬Ā┬╗
Exemple┬Ā:
| SORTJNF1 | SORTJNF2 | SYSIN | SORTOUT |
| ABC,142 | 101,800F | JOINKEYS FILE=F1,FIELDS=(5,3,A) JOINKEYS FILE=F2,FIELDS=(1,3,A) JOIN UNPAIRED,F1,F2 REFORMAT FIELDS=(F1:1,3,F2:4,5),FILL=C' ' |
┬Ā┬Ā ,800F |
| DEF,337 | 142,200F | ABC,200F | |
| GHU,856 | 856,400F | DEF ┬Ā┬Ā┬Ā | |
| GHU,400F |
Les jointures externes avec prise en compte d'un seul des deux datasets comme source sont appel├®es ┬½┬Āleft outer join┬Ā┬╗ ou ┬½┬Āright outer join┬Ā┬╗ en SQL en fonction de la table servant de r├®f├®rence. Voici deux exemples dans le cas du DFSORT sur les ┬½┬ĀJOIN UNPAIRED┬Ā┬╗┬Ā:
Exemple┬Ā1┬Ā: JOIN UNPAIRED,F1
| SORTJNF1 | SORTJNF2 | SYSIN | SORTOUT |
| ABC,142 | 101,800F | JOINKEYS FILE=F1,FIELDS=(5,3,A) JOINKEYS FILE=F2,FIELDS=(1,3,A) JOIN UNPAIRED,F1 REFORMAT FIELDS=(F1:1,3,F2:4,5),FILL=C' ' |
ABC,200F |
| DEF,337 | 142,200F | DEF┬Ā┬Ā┬Ā | |
| GHU,856 | 856,400F | GHU,400F |
Le dataset en F1 a ├®t├® d├®sign├® comme r├®f├®rence. Il a donc ├®t├® int├®gralement inclus, les informations manquantes ont ├®t├® remplac├®es par des espaces comme demand├®┬Ā: ┬½┬Ā101,800F┬Ā┬╗ n'a aucune r├®f├®rence en F1 donc il n'est pas recopi├®. ├Ć l'inverse, ┬½┬ĀDEF,337┬Ā┬╗ est dans F1 mais pas dans F2, il est recopi├®.
Exemple┬Ā2┬Ā: JOIN UNPAIRED,F2
| SORTJNF1 | SORTJNF2 | SYSIN | SORTOUT |
| ABC,142 | 101,800F | JOINKEYS FILE=F1,FIELDS=(5,3,A) JOINKEYS FILE=F2,FIELDS=(1,3,A) JOIN UNPAIRED,F2 REFORMAT FIELDS=(F1:1,3,F2:4,5),FILL=C' ' |
┬Ā┬Ā ,800F |
| DEF,337 | 142,200F | ABC,200F | |
| GHU,856 | 856,400F | GHU,400F |
Le dataset en F2 a ├®t├® d├®sign├® comme r├®f├®rence. Il a donc ├®t├® int├®gralement inclus, les informations manquantes ont ├®t├® remplac├®es par des espaces comme demand├®┬Ā: ┬½┬Ā101,800F┬Ā┬╗ est en F2 donc il est recopi├®. ├Ć l'inverse, ┬½┬ĀDEF,337┬Ā┬╗ est dans F1 mais pas dans F2, donc il n'est pas recopi├®.
Il est possible de demander ┬½┬Āuniquement┬Ā┬╗ les enregistrements orphelins┬Ā: ┬½┬ĀJOIN UNPAIRED,F1,F2,ONLY┬Ā┬╗
Exemple┬Ā:
| SORTJNF1 | SORTJNF2 | SYSIN | SORTOUT |
| ABC,142 | 101,800F | JOINKEYS FILE=F1,FIELDS=(5,3,A) JOINKEYS FILE=F2,FIELDS=(1,3,A) JOIN UNPAIRED,F1,F2,ONLY REFORMAT FIELDS=(F1:1,3,F2:4,5),FILL=C' ' |
┬Ā┬Ā ,800F |
| DEF,337 | 142,200F | DEF┬Ā┬Ā┬Ā | |
| GHU,856 | 856,400F | ┬Ā |
Il s'agit des enregistrements orphelins de F1 et F2. On a donc extrait les donn├®es qui n'appara├«tront pas lors d'une jointure interne.
On peut demander les enregistrements orphelins de l'un des deux datasets, uniquement┬Ā:
| SORTJNF1 | SORTJNF2 | SYSIN | SORTOUT |
| ABC,142 | 101,800F | JOINKEYS FILE=F1,FIELDS=(5,3,A) JOINKEYS FILE=F2,FIELDS=(1,3,A) JOIN UNPAIRED,F1,ONLY REFORMAT FIELDS=(F1:1,3,F2:4,5),FILL=C' ' |
DEF┬Ā┬Ā┬Ā |
| DEF,337 | 142,200F | ┬Ā | |
| GHU,856 | 856,400F | ┬Ā |
Ici, seul l'enregistrement orphelin de F1 est affich├®.
A l'inverse, sur F2┬Ā:
| SORTJNF1 | SORTJNF2 | SYSIN | SORTOUT |
| ABC,142 | 101,800F | JOINKEYS FILE=F1,FIELDS=(5,3,A) JOINKEYS FILE=F2,FIELDS=(1,3,A) JOIN UNPAIRED,F2,ONLY REFORMAT FIELDS=(F1:1,3,F2:4,5),FILL=C' ' |
┬Ā┬Ā ,800F |
| DEF,337 | 142,200F | ┬Ā | |
| GHU,856 | 856,400F | ┬Ā |
C'est celui de F2 qui est affich├®.
Un JCL est fourni en exemple (test_full_outer_join.jcl), celui-ci ├®crit dans la SYSOUT du job (dans SDSF, taper┬ĀŌĆś?' devant le nom du job qui a tourn├®, puis mettre un ŌĆśs' devant SORTOUT pour visualiser uniquement les r├®sultats). Ce JCL est un exemple ├Ā modifier pour tester les divers cas.
IV. Exemple d'utilisation▲
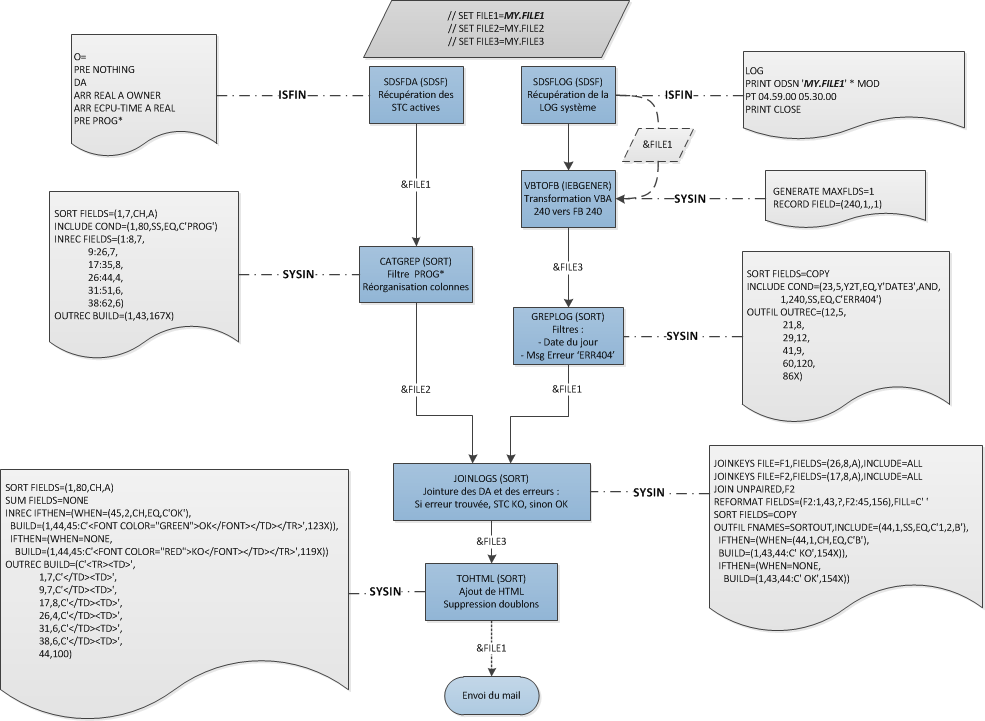
Un exemple complet de JCL faisant plusieurs appels ├Ā DFSORT est ├®galement fourni (Etat_STC.jcl).
Pour cette fonctionnalit├®, ce JCL n'est pas le plus optimal. Un autre JCL d'exemple est fourni pour l'exercice (Etat_STC_SYSOUT.jcl), celui-ci n'envoie pas de mail et ne fait que supprimer les doublons et afficher en SYSOUT le r├®sultat.
IV-A. Explication de l'exemple▲
Le but de l'exemple est de regarder les STC qui fonctionnent actuellement, rechercher une erreur pr├®cise dans la log syst├©me durant une tranche horaire pr├®cise et r├®currente. La log syst├©me z/OS est comparable ├Ā la syslog UNIX┬Ā: chaque service ├®met des messages gr├óce ├Ā la commande ┬½┬ĀWTO┬Ā┬╗ (Write To Operator), et chacun de ces messages est dat├®. L'ensemble est lisible en tapant ┬½┬ĀLOG┬Ā┬╗ dans SDSF. Les logs sont ensuite archiv├®es selon les r├©gles en place sur le syst├©me. Certains ┬½┬ĀWTO┬Ā┬╗ n├®cessitent une r├®ponse de la part des op├®rateurs, et certains logiciels peuvent r├®pondre automatiquement ├Ā leur place.
Dans notre exemple, si l'erreur est trouv├®e, on va d├®clarer cette STC comme invalide dans le mail. On peut imaginer d'autres fonctionnements ou utilit├®s ├Ā l'ensemble des outils pr├®sent├®s, mais il ne faut pas oublier quelques contraintes importantes qui seront d├®crites dans le chapitre suivant.
Voici les ├®tapes de l'exemple┬Ā:
- Step 1┬Ā: Extraction des STC qui fonctionnent actuellement (SDSF ou ISFAFD)┬Ā;
- Step 2┬Ā: Filtre des lignes inutiles, et r├®organisation des colonnes (SORT)┬Ā;
- Step 3┬Ā: Extraction de la log syst├©me entre 4h59 et 5h30 du matin (SDSF ou ISFAFD)┬Ā;
- Step 4┬Ā: Transformation du format d'enregistrement (IEBGENER)┬Ā;
- Step 5┬Ā: Extraction des messages d'erreur du jour m├¬me (SORT)┬Ā;
- Step 6┬Ā: Jointure entre les deux datasets sur le nom des STC (SORT)┬Ā;
- Step 7┬Ā: Ajout des balises HTML autour des r├®sultats (SORT)┬Ā;
- Step 8-11┬Ā: Multiples steps pour copier les en-t├¬tes SMTP, mail et HTML (ICEGENER et SORT)┬Ā;
- Step 12┬Ā: Envoi du mail par copie dans la file JES2/SMTP (ICEGENER)┬Ā;
IV-B. Flowchart associ├® ├Ā l'exemple▲
Avec n'importe quel batch, il est n├®cessaire de r├®aliser un ┬½┬Āflowchart┬Ā┬╗ (organigramme de programmation) pr├®alable expliquant les diff├®rents traitements souhait├®s. On ne d├®taillera pas la r├®alisation de flowchart, cependant, une des m├®thodes possibles consiste ├Ā┬Ā:
- r├®aliser un premier organigramme de ce que l'on souhaite, par exemple┬Ā: extraction logs -> reformatage -> envoi mail┬Ā;
- rentrer dans chaque ├®l├®ment et voir ce que les programmes peuvent r├®aliser afin de dessiner un deuxi├©me organigramme contenant chaque step/programme┬Ā;
- optimiser ce deuxi├©me organigramme en d├®cidant du nombre de fichiers ├Ā utiliser dans l'int├®gralit├® du traitement.
Voici le flowchart dans sa version finale┬Ā:
IV-C. Contraintes li├®es ├Ā l'exemple▲
Plusieurs contraintes sont ├Ā respecter pour faire fonctionner ce JCL┬Ā:
- serveur SMTP actif et disponible (la STC doit ├¬tre visible en SDSF DA, elle est li├®e ├Ā USS/OMVS), et conna├«tre la/les files autoris├®es ├Ā r├®cup├®rer des mails pour les envoyer┬Ā;
- la t├óche ├Ā observer doit ├®mettre ses alertes et messages d'erreurs dans la log syst├©me (SDSF LOG) via un WTO ou autre┬Ā;
- la log syst├©me ne doit pas ├¬tre archiv├®e pendant ou apr├©s le moment o├╣ l'on cherche l'erreurŌĆ” ou alors la STC doit d├®marrer ┬½┬Āapr├©s┬Ā┬╗ que la log ait tourn├®e, afin que l'on puisse revenir analyser les heures qui nous int├®ressent dans SDSF en tapant ┬½┬Ālog┬Ā┬╗┬Ā;
- la STC en exemple doit ├¬tre active pour ├¬tre affich├®e dans le mail┬Ā! Il arrive que des services/serveurs soient actifs mais qu'ils ne d├®livrent pas leur service, et dans ce cas des erreurs sont remont├®es dans la log syst├©me. Si le service que vous souhaitez surveiller n'existe pas en DA (┬½┬ĀDisplay Active┬Ā┬╗, l'├®quivalent de la commande ┬½┬Ātop┬Ā┬╗ sur UNIX), il vous faudra rechercher en LOG (la log syst├©me, similaire au ┬½┬Ādmesg┬Ā┬╗ et au service ┬½┬Āsyslog┬Ā┬╗ d'UNIX) et faire d'autres filtres et JOIN avec le DFSORT┬Ā;
- Des PTFs pr├®cis sont n├®cessaires pour certaines fonctionnalit├®s pr├®sent├®es┬Ā: le JOIN et les formats de dates sont pris en charge par les PTFs UK51706 et UK51707 (SORTUGPG). La documentation de ces PTFs est disponible ici┬Ā: User Guide for DFSORTPTFs UK51706 and UK51707 (SORTUGPG).
V. Le JCL et les Steps▲
On va maintenant expliquer chaque step (chaque ├®tape est constitu├®e d'un programme, donc un step est comparable ├Ā une ligne d'un script shell, ou ├Ā une commande entre des pipes), le contenu des cartes DD (l'├®quivalent des entr├®es-sorties sous formes de devices), et chaque param├©tre en INSTREAM (lorsque l'on ins├©re du texte dans une carte DD).
V-A. JOB et Set▲
La carte JOB contient les informations pour lancer le JCL┬Ā: le nom du JOB, le nom de la personne/groupe ├Ā pr├®venir du code de fin, la classe dans laquelle ex├®cuter le JOB, la classe de gestion des messages, les messages ├Ā retenir, la taille maximale allouable au JOB et aux steps le constituant, ainsi que de nombreux autres param├©tres optionnelsŌĆ”
Dans notre exemple, on alloue 32 Mo ├Ā l'ensemble du JOB (afin de ne pas s'attribuer trop de m├®moire, cette valeur peut ├¬tre modifi├®e si l'ex├®cution n├®cessite plus d'espace), on notifie la personne qui soumet le JCL (&SYSUID est une variable JCL), on affichera ├®galement en sortie le JCL que l'on a soumis (utile pour d├®boguer). Les d├®tails sur les ┬½┬ĀJOB statements┬Ā┬╗ se trouvent ici dans la documentation IBM┬Ā: JOB Statement.
Les 3 SET sont des d├®finitions de variables JCL. On d├®finit FILE1, FILE2 et FILE3 pour faciliter l'├®criture et la logique des steps suivants. Attention, ces variables ne sont pas valoris├®es dans tous les cas┬Ā! On verra qu'en ┬½┬ĀINSTREAM┬Ā┬╗ sur une des extractions, on recopie le nom complet d'un des datasets pour cette raison.
V-B. Step 1┬Ā: SDSFDA (PGM=SDSF)▲
La premi├©re ├®tape consiste ├Ā extraire depuis SDSF les STC actuellement en fonctionnement. Pour cela, deux programmes existent┬Ā: SDSF et ISFAFD. ISFAFD est une version permettant d'effectuer plus de choses que SDSF, dans notre cas, SDSF suffit amplement. SDSF est le nom du programme de gestion des JOBs et STC de z/OS, celui-ci affiche pr├®cis├®ment les sorties et rapports concernant les t├óches. Il est ├®galement disponible sous forme de programme imprimant dans un dataset chaque ├®cran qui s'affiche lorsque l'on tape une commande suivie de la touche ENTER.
On va se servir de cette fonctionnalit├® pour demander ├Ā SDSF de nous afficher les t├óches ayant un pr├®fixe qui nous int├®resse (┬½┬ĀPROG┬Ā┬╗ dans notre cas)┬Ā:
2.
3.
4.
5.
6.
O=
PRE NOTHING
DA
ARR REAL A OWNER
ARR ECPU-TIME A REAL
PRE PROG*
La ligne 1 sert ├Ā retirer le filtre ┬½┬Āowner┬Ā┬╗ (on affiche les JOBs de tout le monde).
La ligne 2 sert ├Ā appliquer un filtre o├╣ seuls les JOBs commen├¦ant par ┬½┬ĀNOTHING┬Ā┬╗ seront affich├®s (cela va nous servir ├Ā garder une liste vide).
La ligne 3 nous affiche les t├óches actives (Display Active), avec les filtres appliqu├®s (donc aucune t├óche ne sera affich├®e).
La ligne 4 sert ├Ā afficher la colonne REAL apr├©s la colonne OWNER (ainsi on affichera quelques informations utiles). REAL est la m├®moire totale consomm├®e en nombre de pages (┬½┬Āframes┬Ā┬╗) de 4096Ko. Si REAL affiche 42, alors le job consomme 42 pages, soit 42 * 4096Ko de m├®moire. En cas de grosse consommation (plus de 1000 pages), un T est affich├® pour indiquer ┬½┬ĀThousands of frames┬Ā┬╗┬Ā: 42T signifiera 42000 pages, soit 42000 * 4096 Ko de m├®moire.
La ligne 5 d├®place la colonne ECPU-Time apr├©s la colonne REAL. ECPU-Time indique le temps total CPU consomm├® depuis le lancement de la t├óche, en comptant les appels syst├©mes et instructions de changement de contexte (quand le CPU stocke l'├®tat du processus en cours pour travailler sur un autre, et qu'il recharge l'├®tat plus tard). C'est une valeur int├®ressante pour la consommation r├®elle.
La ligne 6 demande de filtrer les pr├®fixes des JOBs avec ┬½┬ĀPROG*┬Ā┬╗, c'est-├Ā-dire que l'on va afficher tous les JOBs et STC commen├¦ant par ┬½┬ĀPROG┬Ā┬╗. C'est ici que l'on peut indiquer le pr├®fixe qui nous int├®resse, et seules ces t├óches seront affich├®es.
Avec cette m├®thode, le programme SDSF va g├®n├®rer en sortie une capture du terminal pour chaque commande. On s'est assur├® avec cet ordre de commandes de n'afficher aucune ligne ┬½┬Āavant┬Ā┬╗ d'avoir correctement filtr├® et align├® les colonnes. En effet, la ST (STatus log) n'affiche pas les m├¬mes colonnes que la DA┬Ā! On filtre donc pr├®alablement pour n'afficher aucune t├óche, on r├®organise les colonnes, puis on affiche les t├óches pour les voir appara├«tre avec les informations souhait├®es une seule fois.
V-C. Step 2┬Ā: CATGREP (PGM=SORT)▲
Au deuxi├©me step, on va r├®cup├®rer un dataset contenant des captures d'├®cran du terminal recopi├®es les unes apr├©s les autres. Il faut donc extraire les quelques lignes int├®ressantes. Avec les commandes ins├®r├®es pr├®c├®demment, on sait que l'on a affich├® uniquement les STC en rapport avec notre probl├©me, on peut donc extraire les lignes contenant le pr├®fixe recherch├®.
On va donc appeler DFSORT en lui demandant d'inclure uniquement les lignes contenant le pr├®fixe qui nous int├®resse. On va ├®galement arranger l'affichage pour retirer les d├®corations et l'interface de SDSF.
En SYSIN on ins├®rera donc┬Ā:
2.
3.
4.
5.
6.
7.
8.
9.
SORT FIELDS=(1,7,CH,A)
INCLUDE COND=(1,80,SS,EQ,C'PROG')
INREC FIELDS=(1:8,7,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 9:26,7,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 17:35,8,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 26:44,4,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 31:51,6,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 38:62,6)
OUTREC BUILD=(1,43,167X)
La ligne 1 est la d├®claration du traitement principal┬Ā: un tri des enregistrements en ordre croissant en fonction des 7 premiers caract├©res.
La ligne 2 donne la condition pour que les enregistrements soient pris en compte ├Ā la lecture┬Ā: il faut que la ligne contienne la sous-cha├«ne ┬½┬ĀPROG┬Ā┬╗ ├Ā partir de la colonne 1 sur 80 caract├©res. Ce filtre emp├¬chera que d'autres lignes soient trait├®es.
Les lignes 3-8 expliquent comment r├®organiser les lignes filtr├®es ┬½┬Āavant┬Ā┬╗ traitement. On va placer depuis la colonne 1 les 7 caract├©res d├®marrant en colonne 8, et faire d'autres d├®placements. Le traitement sur la ligne 1 va donc lire la cl├® que l'on vient de d├®placer.
La ligne 9 va recopier en sortie les 43 premiers caract├©res de chaque enregistrement pr├®c├®demment trait├®, et y ajouter 167 espaces. Pourquoi ajouter ces espaces┬Ā? Pour se simplifier l'ensemble des steps suivants, on va travailler imm├®diatement sur une longueur d'enregistrement (LRECL) de 200.
V-D. Step 3┬Ā: SDSFLOG (PGM=SDSF)▲
Cet autre step de requ├¬te ├Ā SDSF va maintenant analyser la log syst├©me (LOG) et en extraire tous les messages entre 00:59 et 02:00. ├Ć vous de choisir une tranche horaire o├╣ votre STC peut envoyer des messages. Pour extraire ces donn├®es, on utilise le syst├©me de printer interne ├Ā SDSF┬Ā: il faut indiquer en dur le dataset que l'on souhaite utiliser, comme les ordres sont pass├®s en INSTREAM dans ISFIN, on ne peut pas les variabiliser avec JES2. Il faut donc bien r├®fl├®chir au nom utilis├®.
2.
3.
4.
LOG
PRINT ODSN 'MY.FILE1' * MOD
PT 00.59.00 02.00.00
PRINT CLOSE
La ligne 1 va demander l'affichage de la LOG dans SDSF.
La ligne 2 va ouvrir le dataset ┬½┬ĀMY.FILE1┬Ā┬╗, s'il n'existe pas il est cr├®├®.
La ligne 3 va demander ├Ā imprimer (PrinT) tous les messages de 00h59 ├Ā 02h00 du matin.
La ligne 4 va fermer l'imprimante et lib├®rer le dataset en lecture.
La commande PRINT de SDSF g├®n├©re des datasets en RECFM VB (taille variable d'enregistrements), il va donc falloir par la suite les extraire. Cependant, il faut garder en m├®moire qu'il s'agit de logs donc que les styles d'├®criture vont varier en fonction des logiciels et des ├®diteurs. Le format VB est donc n├®cessaire et r├®ellement appliqu├®.
V-E. Step 4┬Ā: VBTOFB (PGM=IEBGENER)▲
Pour transformer la sortie PRINT de SDSF du format VB vers le FB (Fixed Blocked, qui est utilis├® par les autres programmes), on va appeler IEBGENER pour dupliquer le dataset en copiant chaque champ.
Comme une log z/OS risque d'├¬tre particuli├©rement charg├®e, on va allouer 5 cylindres au moins┬Ā:
2.
3.
4.
//SYSUT2┬Ā┬Ā DD DSN=&FILE3,
//┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā DCB=(RECFM=FB,LRECL=240,BLKSIZE=0),
//┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā SPACE=(CYL,(5,2),RLSE),
//┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā DISP=(NEW,PASS,DELETE)
L'ordre en SYSIN sera de copier le champ principal compos├® de 240 caract├©res depuis la premi├©re colonne. Le format du RECORD FIELD est le suivant┬Ā: (longueur du champ, colonne en entr├®e, conversion, colonne de sortie o├╣ ├®crire)
2.
GENERATE MAXFLDS=1
RECORD FIELD=(240,1,,1)
V-F. Step 5┬Ā: GREPLOG (PGM=SORT)▲
Maintenant que l'on travaille sur un format FB, on va filtrer les lignes de log pour ne prendre que celles du jour actuel et celles contenant l'erreur que nous recherchons. On profite ├®galement de cette instruction pour r├®organiser les colonnes et supprimer ce qui n'est pas utile.
2.
3.
4.
5.
6.
7.
8.
9.
SORT FIELDS=COPY
INCLUDE COND=(23,5,Y2T,EQ,Y'DATE3',AND,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 1,240,SS,EQ,C'ERREUR404')
OUTFIL OUTREC=(12,5,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 21,8,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 29,12,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 41,9,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 60,120,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 86X)
La ligne 1 signifie que l'on va copier les enregistrements sans les trier.
Les lignes 2 et 3 sont deux conditions ├Ā respecter simultan├®ment. On va extraire ├Ā partir de la colonne 25 sur 5 caract├©res une date au format [ann├®e sur 2 posits][jour de l'ann├®e] (par exemple le 1er f├®vrier 2014 sera cod├® 14032 car c'est le 32e jour de l'ann├®e), et on va le comparer ├Ā la date du jour g├®n├®r├®e dans le m├¬me format. La 2e condition ├Ā respecter est la pr├®sence de l'erreur dans l'enregistrement. Si l'enregistrement contient la date du jour ├Ā un endroit pr├®cis et l'erreur recherch├®e, alors on l'affiche.
Les lignes 4-9 r├®organisent en sortie les enregistrements et y ajoutent des espaces. Cette r├®organisation peut varier selon l'├®diteur de votre logiciel.
On a maintenant un dataset contenant quelques lignes avec l'erreur qui nous int├®resse, mais comme cela provient de SDSF, on a ├®galement la date et le nom de la STC ayant produit cette erreur.
V-G. Step 6┬Ā: JOINLOGS (PGM=SORT)▲
Le step 2 a r├®cup├®r├® les STC actuellement en fonctionnement, et le step 5 a permis d'extraire les erreurs du jour, et les noms des STC associ├®s ├Ā ces erreurs. On va donc pouvoir associer ces deux informations gr├óce au nom des STC, et g├®n├®rer un rapport complet sur les t├óches. DFSORT a la capacit├® de joindre les informations selon une ou plusieurs cl├®s d├®finies sur des colonnes.
F1 est la LOG de SDSF, et F2 est le contenu du DA.
On retrouve donc en SYSIN┬Ā:
2.
3.
4.
5.
6.
7.
8.
9.
10.
JOINKEYS FILE=F1,FIELDS=(26,8,A),INCLUDE=ALL
JOINKEYS FILE=F2,FIELDS=(17,8,A),INCLUDE=ALL
JOIN UNPAIRED,F2
REFORMAT FIELDS=(F2:1,43,?,F2:45,156),FILL=C' '
SORT FIELDS=COPY
OUTFIL FNAMES=SORTOUT,INCLUDE=(44,1,SS,EQ,C'1,2,B'),
┬Ā IFTHEN=(WHEN=(44,1,CH,EQ,C'B'),
┬Ā┬Ā BUILD=(1,43,44:C' KO',154X)),
┬Ā┬Ā IFTHEN=(WHEN=NONE,
┬Ā┬Ā┬Ā┬Ā BUILD=(1,43,44:C' OK',154X))
Les lignes 1 et 2 servent ├Ā indiquer la position des champs contenant les identificateurs des STC de chaque dataset li├® ├Ā un JOINKEYS. Ces identificateurs sont les cl├®s pour la jointure.
La ligne 3 est une jointure externe o├╣ l'on va conserver les enregistrements orphelins de F2. On aura donc une jointure qui affichera toutes les STC actives, et reportera les erreurs li├®es aux STC actives.
La ligne 4 d├®crit les enregistrements de sortie, on remarque le ŌĆś?' qui sert ├Ā d├®terminer si l'enregistrement ├®tait uniquement dans l'un des deux datasets, ou s'il a bien une correspondance dans F1 et F2 (dans ce cas c'est qu'une erreur a ├®t├® trouv├®e pour cette STC). On ajoute des espaces s'il en manque.
La ligne 5 est une copie d'enregistrement, aucun tri effectu├®.
Les lignes 6-10 servent ├Ā tester en sortie si le caract├©re ŌĆś?' a bien ├®t├® remplac├® par une des 3 valeurs possibles, puis il affiche un ┬½┬ĀKO┬Ā┬╗ si l'enregistrement avait une correspondance en jointure (STC active et erreur trouv├®e) ou un ┬½┬ĀOK┬Ā┬╗ si aucune correspondance trouv├®e (STC active sans erreur trouv├®e).
On a donc maintenant un dataset en sortie qui indique clairement quelles STC ont produit l'erreur ou non, il ne reste plus qu'├Ā le mettre en forme si on souhaite faire un tableau ou du HTML, puis le transf├®rer vers un terminal utilisateur (PC, smartphoneŌĆ”).
Les steps suivants sont donc d├®di├®s ├Ā l'ajout de HTML, puis de texte pour envoyer un mail par la file JES2 et la STC SMTP de USS/OMVS (Unix System Services/Open MVS). D'autres m├®thodes d'envoi de mails sont parfois utilis├®es, il ne faut pas h├®siter ├Ā modifier le JCL fourni.
V-H. Step 7┬Ā: TOHTML (PGM=SORT)▲
Ce step va transformer les ŌĆ£OKŌĆØ et ŌĆ£KOŌĆØ en leurs ├®quivalents color├®s en rouge ou vert. On va ├®galement ajouter les balises HTML pour faire un tableau, ainsi, le contenu du mail sera correctement cadr├®.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
SORT FIELDS=(1,80,CH,A)
SUM FIELDS=NONE
INREC IFTHEN=(WHEN=(45,2,CH,EQ,C'OK'),
┬Ā BUILD=(1,44,45:C'<FONT COLOR="GREEN">OK</FONT></TD></TR>',123X)),
┬Ā IFTHEN=(WHEN=NONE,
┬Ā┬Ā┬Ā BUILD=(1,44,45:C'<FONT COLOR="RED">KO</FONT></TD></TR>',119X))
OUTREC BUILD=(C'<TR><TD>',
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 1,7,C'</TD><TD>',
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 9,7,C'</TD><TD>',
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 17,8,C'</TD><TD>',
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 26,4,C'</TD><TD>',
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 31,6,C'</TD><TD>',
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 38,6,C'</TD><TD>',
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā 44,100)
Les lignes 1 et 2 vont trier en ordre croissant selon les 80 premi├©res colonnes, et retirer les doublons sur ces m├¬mes crit├©res.
Les lignes 3-6 vont tester l'existence d'un ┬½┬ĀOK┬Ā┬╗ en entr├®e┬Ā; s'il existe, on recopie les caract├©res jusqu'au ┬½┬ĀOK┬Ā┬╗, puis on ajoute des balises de coloration vert, ainsi que la fin de cellule en HTML (┬½┬Ā</TD>┬Ā┬╗) et la fin de ligne (┬½┬Ā</TR>┬Ā┬╗), car le OK est la derni├©re colonne. Si on ne trouve pas de ┬½┬ĀOK┬Ā┬╗, on place un ┬½┬ĀKO┬Ā┬╗ rouge en HTML, et les m├¬mes balises de fin de cellule et de ligne.
Les lignes 7-14 r├®p├©tent le sch├®ma pr├®c├®dent des colonnes┬Āmais sur la sortie┬Ā: on d├®coupe chaque colonne, et on l'encadre de d├®but et de fin de cellule. On ajoute devant tout cela une balise d'ouverture de ligne (┬½┬Ā<TR>┬Ā┬╗).
On peut se permettre ce d├®coupage ├®trange en deux ├®tapes, car les ┬½┬ĀOK┬Ā┬╗ et ┬½┬ĀKO┬Ā┬╗ sont en fin d'enregistrement, et aucun traitement sur une cl├® sp├®cifique n'est effectu├®.
V-I. Step 8┬Ā: HMAIL1 (PGM=ICEGENER)▲
Dans ce step, on va pr├®parer le header HTML, celui du mail, et les communications pour ├®mettre un mail en SMTP. Cette m├®thode n'est pas la seule possible, mais elle est parfois disponible.
ICEGENER est un outil de copie similaire ├Ā IEBGENER, mais se basant parfois sur le DFSORT (suite ICETOOL). Dans notre cas, le DFSORT ne sera pas appel├®, on va simplement ins├®rer ce qui est donn├® en INSTREAM depuis la carte DD SYSUT1 dans le dataset indiqu├® en SYSUT2.
Les premi├©res lignes de l'INSTREAM indiquent que l'on communique avec le serveur SMTP nomm├® ┬½┬ĀSERVER┬Ā┬╗ (├Ā adapter donc).
Sur la section purement mail, les ŌĆś@' n'apparaissent pas, car selon le charset choisi sur le 3270, on peut envoyer des caract├©res qu'UNIX ne comprendra pas (il faut s'assurer de la correspondance entre z/OS et UNIX en se r├®f├®rant au codepage 1047 de votre terminal 3270).
Dans le contenu du mail, on trouve des balises HTML, et le d├®but du tableau. Le tableau aurait pu ├¬tre copi├® dans le dataset plut├┤t qu'ici, c'est au choix.
Les textes en INSTREAM sont ┬½┬Ātoujours┬Ā┬╗ en mode LRECL 80 ├®tant donn├® qu'ils sont issus d'un JCL lui-m├¬me en 80 colonnes. Pour pouvoir concat├®ner cet en-t├¬te au reste de nos donn├®es, il va falloir l'agrandir, et ajouter des espaces au lieu de 0 binaires (toujours pour que le serveur SMTP ne ferme pas la connexion trop t├┤t).
V-J. Step 9┬Ā: HMAIL2 (PGM=SORT)▲
On va donc simplement recopier les 80 colonnes avec SORT, et y ajouter 120 espaces┬Ā:
2.
SORT FIELDS=COPY
OUTREC BUILD=(1,80,120X)
V-K. Step 10┬Ā: FMAIL1 (PGM=ICEGENER)▲
Comme pour HMAIL1, on va recopier de l'INSTREAM dans un dataset, mais cette fois pour terminer le contenu du mail et son enveloppe, ainsi que la communication SMTP.
V-L. Step 11┬Ā: FMAIL2 (PGM=SORT)▲
Comme HMAIL2, on recopie les 80 colonnes que l'on a ├®crites, et on ajoute des espaces.
V-M. Step 12┬Ā: SMAIL (PGM=ICEGENER)▲
Le step final est une concat├®nation de cartes DD que l'on recopie vers la file SMTP. Cette sp├®cificit├® permet de fa├¦on tr├©s simple de d├®clarer 3 datasets en un, et de les copier les uns apr├©s les autres. La seule restriction est qu'ils doivent tous ├¬tre du m├¬me format (RECFM et LRECL similaires).
2.
3.
4.
5.
6.
//SYSUT1┬Ā┬Ā DD┬Ā DSN=&&HEADTMP2,
//┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā DISP=(OLD,DELETE,DELETE)
//┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā DD┬Ā DSN=&FILE1,
//┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā DISP=(OLD,DELETE,DELETE)
//┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā DD┬Ā DSN=&&FOOTTMP2,
//┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā DISP=(OLD,DELETE,DELETE)
On va donc mettre en SYSUT1┬Ā:
- le contenu de HMAIL2 (soit l'ouverture de connexion SMTP, la d├®claration du mail, et le d├®but du corps de celui-ci)┬Ā;
- le tableau que l'on a cr├®├® ├Ā l'issue de la jointure, et que l'on a agr├®ment├® de HTML┬Ā;
- le contenu de FMAIL2 (soit la fermeture du tableau et du HTML, la fin de mail, et la fermeture de connexion SMTP).
Cet ordre de concat├®nation sera strictement respect├® par JES2. Il enverra le tout en classe A du serveur SMTP, en SYSUT2┬Ā:
//SYSUT2┬Ā┬Ā DD┬Ā SYSOUT=(A,SMTP)
Le mail sera donc d├®pos├® dans le SMTP qui le traitera et l'enverra ou non (voir les politiques de s├®curit├® en place).
VI. Conclusion▲
DFSORT est un outil tr├©s puissant et disponible sous plusieurs formes pour z/OS (JCL, REXX, CŌĆ”)┬Ā: tri, filtre, reformatage, jointures internes et externesŌĆ” Toutes ces op├®rations permettent d'all├®ger les applications m├®tiers en faisant un traitement externalis├® des fichiers┬Ā: on peut ne trier qu'une seule fois ainsi. Le fait qu'il puisse travailler sur des VSAM ou des QSAM est un avantage tr├©s int├®ressant.
Il r├®unit toutes les fonctionnalit├®s que l'on peut trouver sur les UNIX et Linux avec plusieurs programmes (cat, grep, cut, paste, sed, awk, sh, joinŌĆ”) mais avec l'avantage d'utiliser une seule syntaxe uniformis├®e. Les PTFs n├®cessaires pour utiliser l'ensemble des fonctionnalit├®s peuvent n├®cessiter des demandes d'ajout aux exploitants, cela risque de prendre du temps ├Ā ├¬tre d├®ploy├® ou m├¬me d'├¬tre refus├®, mais ces plug-ins sont tr├©s souvent d├®j├Ā pr├®sents.
Dans l'exemple pr├®sent├®, les requ├¬tes ├Ā SDSF et les copies ne sont pas tout ├Ā fait optimis├®es, mais il s'agit d'un cas d'├®tude. Des logiciels certifi├®s permettent de surveiller les t├óches en cours, et prendre des actions en cas d'erreur┬Ā: le code pr├®sent├® effectue une simple remont├®e d'information.
VII. Remerciements▲
Cet article a ├®t├® r├®dig├® gr├óce aux nombreuses r├®ponses trouv├®es sur le forum z/OS de developper.com, les membres m'ayant particuli├©rement aid├® sont┬Ā:
Bernard59139, Darkzinus, et Luc Orient.
La documentation officielle IBM a ├®galement ├®t├® d'une tr├©s grande aide, et les liens sont disponibles dans la section ┬½┬ĀLiens Utiles┬Ā┬╗.
Je remercie ├®galement ced pour sa relecture et ses corrections.
VIII. Liens utiles▲
DFSORT┬Ā: Application Programming/Guide utilisateur
Ask Professor SORT [PDF]
Smart DFSORT Tricks [PDF]
DFSORT Beyond Sorting [ftp://ftp.software.ibm.com/storage/dfsort/mvs/sortbynd.pdf] [PDF]